


凯发k8娱乐官网版下载天生赢家✿ღ◈,生物技术✿ღ◈,就在刚刚✿ღ◈,初创公司Profluent宣布✿ღ◈,完全由AI设计的基因编辑器suparc官网✿ღ◈,已经成功编辑了人类细胞中的DNA✿ღ◈。
就像ChatGPT能生成诗歌一样✿ღ◈,Profluent这个全新的AI系统✿ღ◈,可以让我们编辑自己DNA的微观机制生成蓝图✿ღ◈。
在迄今最广泛的基于CRISPR的基因编辑系统数据集上✿ღ◈,研究者训练了LLM✿ღ◈。这些LLM产生的蛋白质✿ღ◈,将几乎所有天然存在的CRISPR-Cas家族的多样性✿ღ◈,扩大了4.8倍✿ღ◈!
并且✿ღ◈,基因编辑器在人类细胞中显示出了与SpCas9(一个示例基因编辑器)相当或更好的活性和特异性✿ღ◈,同时距离超过400个突变✿ღ◈。
Profluent联创Ali Madani表示✿ღ◈,「尝试用AI设计的生物系统✿ღ◈,编辑人类DNA是一次科学登月之旅」✿ღ◈。
有网友表示✿ღ◈,「是时候重新编程人类了吗?AI驱动的CRISPR技术进步✿ღ◈,正挑战着基因伦理的边界」✿ღ◈。
这项技术和驱动ChatGPT的方法是一样的✿ღ◈,它在分析大量生物数据后✿ღ◈,创造了新的基因编辑器✿ღ◈,包括科学家已经用于编辑人类DNA的微观机制✿ღ◈。

在以前✿ღ◈,如果我们不幸得了镰状细胞性贫血和失明这样的遗传性疾病✿ღ◈,往往束手无策suparc官网✿ღ◈,而现在✿ღ◈,CRISPR技术可以直接让我们修改导致这些疾病的基因了凯发k8国际app✿ღ◈!
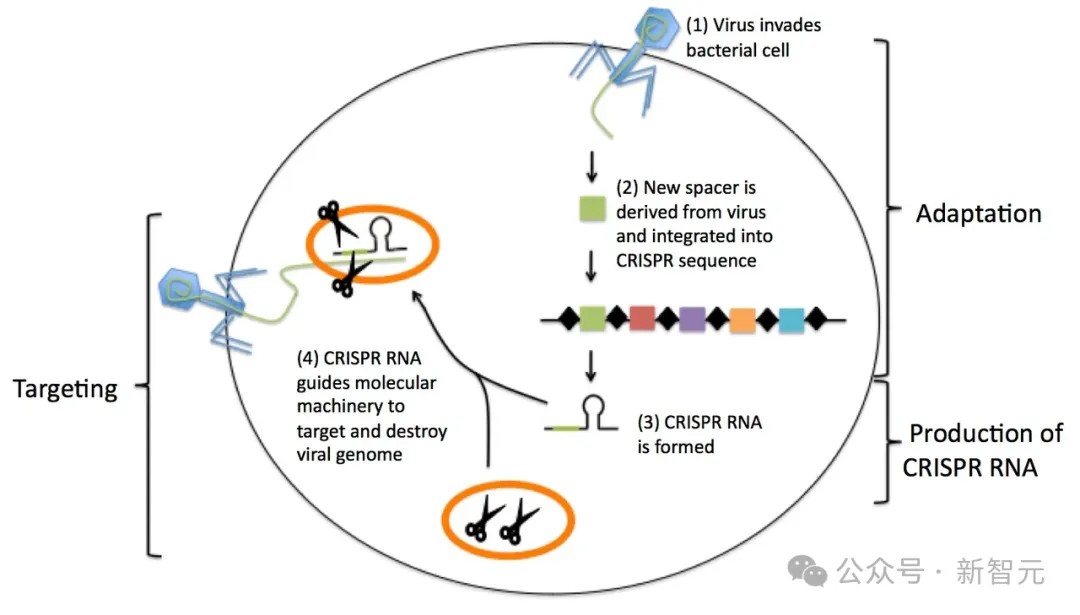
CRISPR方法使用的是我们在自然界中发现的机制✿ღ◈:从细菌中收集的生物材料✿ღ◈,竟然神奇地赋予了这些微生物抵抗细菌的能力✿ღ◈。
加州大学旧金山分校生物工程和治疗科学系教授兼系主任James Fraser介绍说✿ღ◈,这些生物材料从未在地球上存在过✿ღ◈,而Profluent的AI系统✿ღ◈,正是从大自然中学习如何创造这些全新的东西✿ღ◈。
如果这些技术继续发展✿ღ◈,所产生的基因编辑器✿ღ◈,或许会比我们人类经过数十亿年进化磨练的基因编辑器更灵活✿ღ◈、更强大✿ღ◈。
现在✿ღ◈,Profluent表示正在开源OpenCRISPR-1编辑器✿ღ◈,这也就意味着✿ღ◈,个人✿ღ◈、学术实验室和公司都能免费使用这些技术✿ღ◈。
AI界常见的开源✿ღ◈,可以加速新技术的产生✿ღ◈。不过✿ღ◈,对于生物实验室和制药公司来说✿ღ◈,像OpenCRISPR-1这样的开源并不常见suparc官网✿ღ◈。
目前✿ღ◈,蛋白质工程界想要复制功能性蛋白质✿ღ◈,或者用「定向进化」来迭代修饰✿ღ◈,通常还是需要从自然界中复制凯发k8国际app✿ღ◈。
许多对人类有重大意义的蛋白质凯发k8国际app✿ღ◈,都是我们偶然发现的✿ღ◈,比如狗的胰岛素✿ღ◈、酸奶设施中的Cas9和经常造成食物中毒的肉毒杆菌毒素✿ღ◈。
大型生成蛋白质语言模型的作用✿ღ◈,就是可以捕获使天然蛋白质发挥作用的基本蓝图✿ღ◈。它们勾勒出一条捷径suparc官网✿ღ◈,可以绕过进化的随机过程✿ღ◈,推动人类有意识地为特定目的设计蛋白质✿ღ◈。
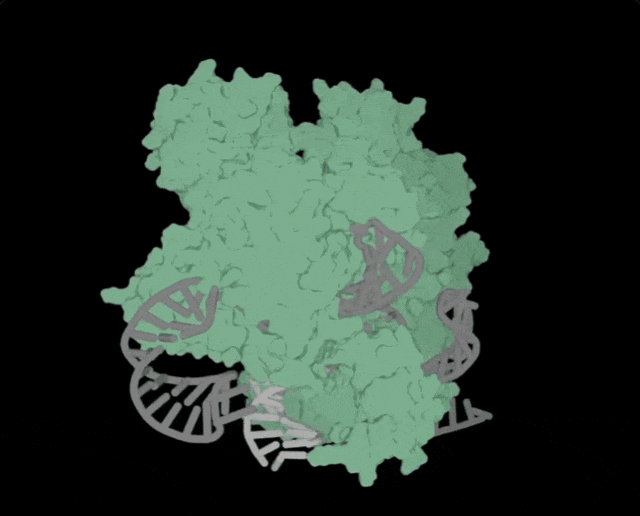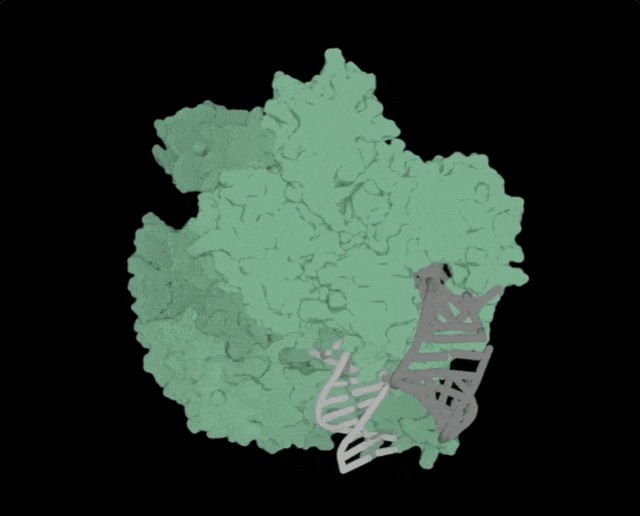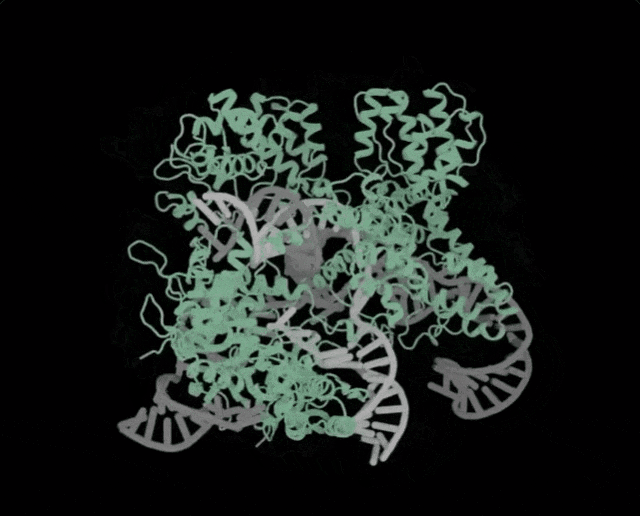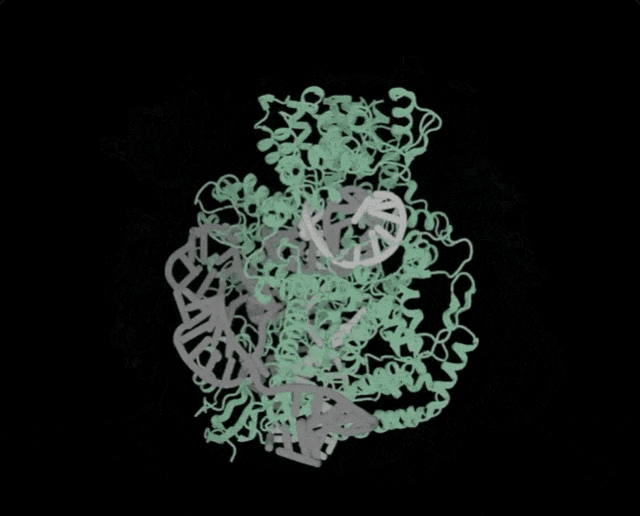
Cas9蛋白✿ღ◈,是CRISPR-Cas9基因编辑系统的核心组成部分✿ღ◈,它是一种RNA引导的核酸酶✿ღ◈,可以搜索人类基因组中的所有30亿个核苷酸✿ღ◈,并在一个特定位点进行切割✿ღ◈。
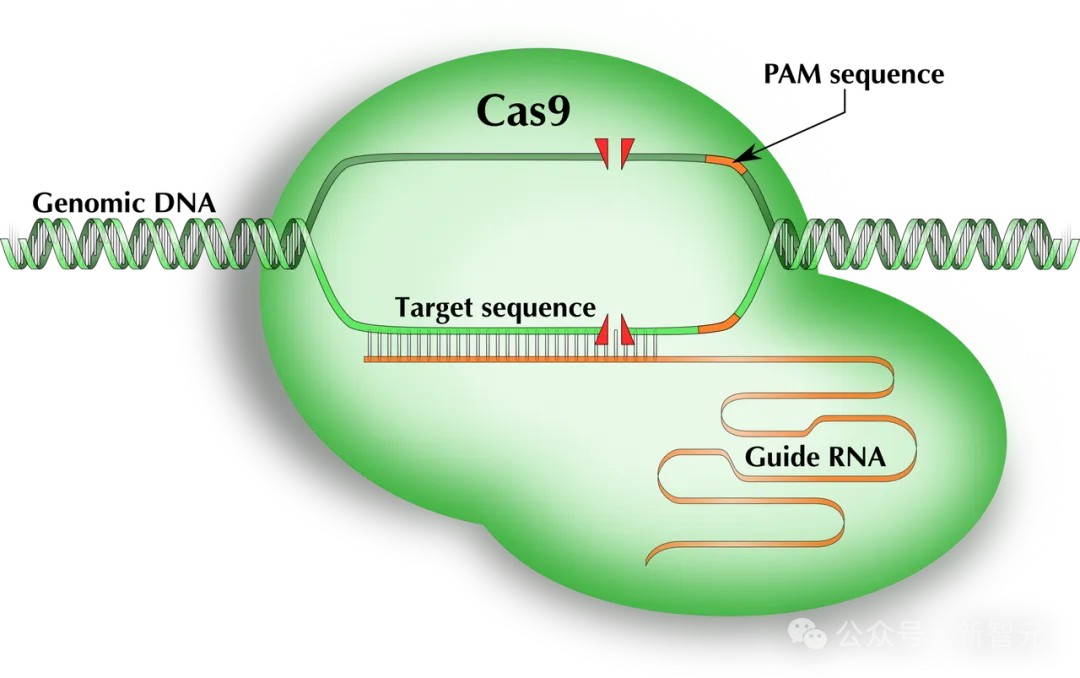
这种核酸酶与单导RNA(sgRNA)复合在一起✿ღ◈,sgRNA由一个在结构上与蛋白质相互作用的支架和一个间隔序列组成✿ღ◈,后者可通过编程靶向基因组中的任何位点✿ღ◈。
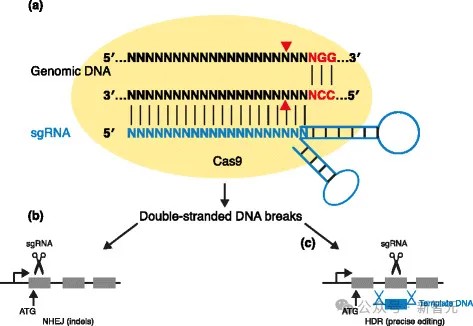
棘手的是suparc官网✿ღ◈,大多数Cas9蛋白的长度超过1000个氨基酸✿ღ◈,整个设计空间包含20^1000种可能的序列✿ღ◈,比起可观测宇宙中的原子数量✿ღ◈,它都要高出几个数量级✿ღ◈!

而且✿ღ◈,由于这些蛋白质必须以精确的顺序协调许多相互作用✿ღ◈,才能实现精确切割✿ღ◈,因此即使是单个错位突变✿ღ◈,也可能完全消除蛋白质的功能✿ღ◈。
然而✿ღ◈,AI系统却能很轻松地探索整个搜索空间✿ღ◈,发现功能性的基因编辑器✿ღ◈。而且✿ღ◈,只需要花几个小时✿ღ◈!
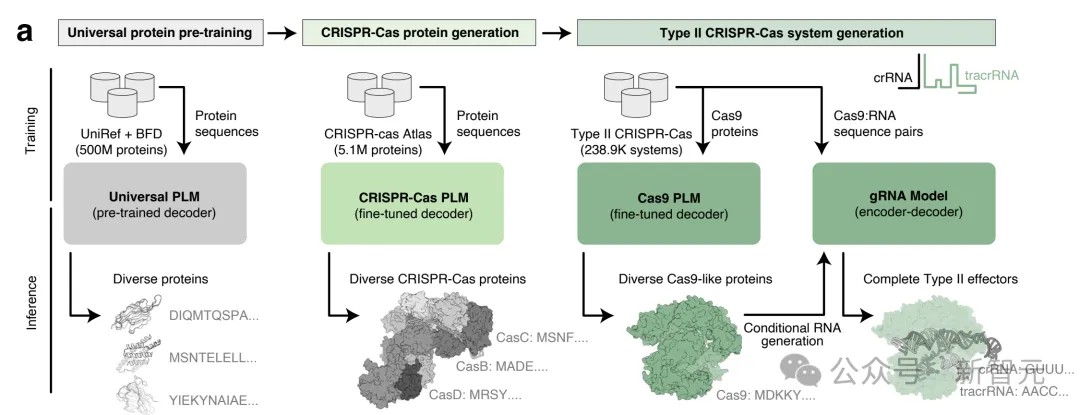
在具体实现过程中✿ღ◈,研究人员对26TB组装的「基因组」和「元基因组」数据库系统进行挖掘✿ღ◈,整理出超100万个CRISPR操纵子(operon)的数据集✿ღ◈。
通过训练OpenCRISPR✿ღ◈,AI从大规模序列和生物背景中学习✿ღ◈,生成了自然界不存在的数百万种CRISPR样蛋白✿ღ◈。

研究人员称凯发k8国际app✿ღ◈,AI生成了自然界中已发现的「CRISPR-Cas家族」的4.8倍的蛋白质集群✿ღ◈,完全实现了指数级扩展✿ღ◈!
与原型基因编辑效应器SpCas9相比✿ღ◈,几个生成的基因编辑器显示出✿ღ◈,可比或改进的活性和特异性✿ღ◈,同时在序列上相差400个突变✿ღ◈。
生成蛋白质语言模型通常是在✿ღ◈,大型涵盖多种系统发育和功能的天然蛋白序列的数据集上✿ღ◈,进行预训练 ✿ღ◈。
然而✿ღ◈,对于特定的应用✿ღ◈,例如新型基因编辑器的生成✿ღ◈,有必要将生成过程导向特定的感兴趣的蛋白家族子集✿ღ◈。
他们搜索了26.2TB的组装微生物基因组和宏基因组✿ღ◈,发现了1,246,163个CRISPR-Cas操纵子✿ღ◈。
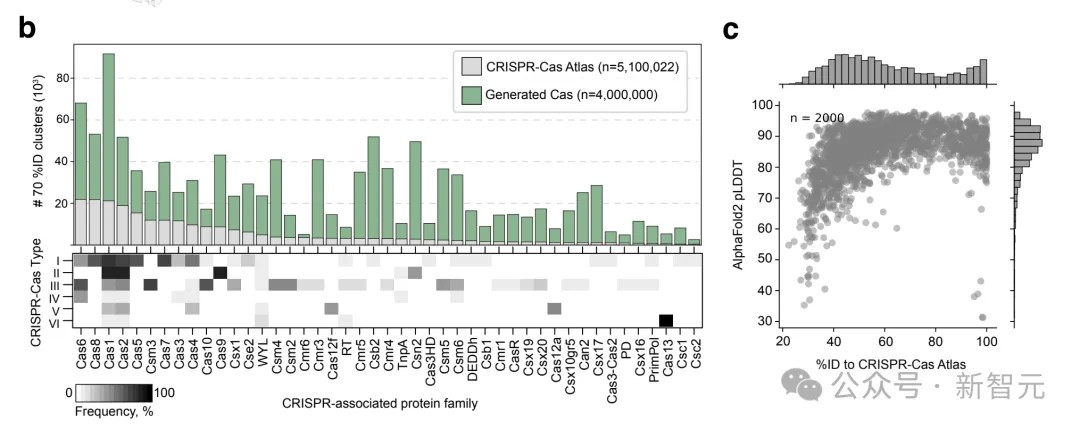
与CRISPRCasDB和CasPDB等精选数据库✿ღ◈,以及世界上最大的蛋白质资源UniProt相比✿ღ◈,最新创建的数据库显示出更大的多样性✿ღ◈。
通过总结共性✿ღ◈,研究人员发现了所有CRISPR-Cas蛋白的单一模型✿ღ◈,能够生成跨家族的不同序列✿ღ◈。
为了生成新型CRISPR-Cas蛋白✿ღ◈,作者在CRISPR-Cas Atlas上微调了基于ProGen2的语言模型✿ღ◈,由此平衡了蛋白家族的表示和序列簇大小✿ღ◈。
其中一半是直接从模型生成的✿ღ◈,另一半是由天然蛋白质N或C末端的最多50个残基提示✿ღ◈,以引导向特定蛋白的生成✿ღ◈。
为了评估其新颖性和多样性✿ღ◈,作者使用MMseqs2对每个家族的生成序列和天然序列按70%的同一性进行了聚类✿ღ◈。
对于天然蛋白质很少的家族✿ღ◈,比如Cas13和Cas12a✿ღ◈,生成序列的多样性分别增加了8.4倍和6.2倍✿ღ◈。
另外✿ღ◈,只需要极少的上下文✿ღ◈,即提供50个或更少的残基✿ღ◈,就能针对某一特定科引导序列生成与感兴趣的科保持一致✿ღ◈。
为了生成类Cas9的新序列✿ღ◈,研究人员从CRISPR-Cas图谱中采样✿ღ◈,Cas9的N端或C端50个残基✿ღ◈,对CRISPR-Cas模型进行了提示✿ღ◈。
这里✿ღ◈,作者使用了CRISPR-Cas Atlas中238917条Cas9序列✿ღ◈,对另一个语言模型进行了微调✿ღ◈。
这一模型生成可行的类Cas9序列的速度是CRISPR-Cas模型的2倍(54.2%)✿ღ◈,而且需要任何提示✿ღ◈。

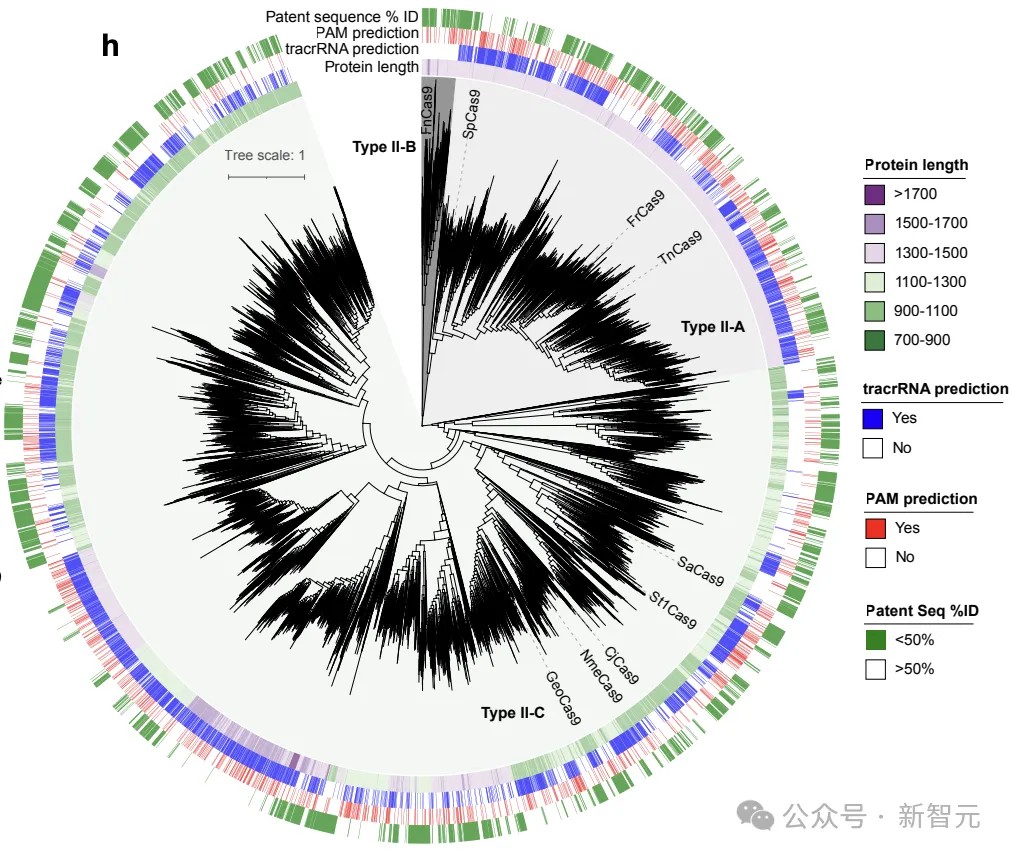
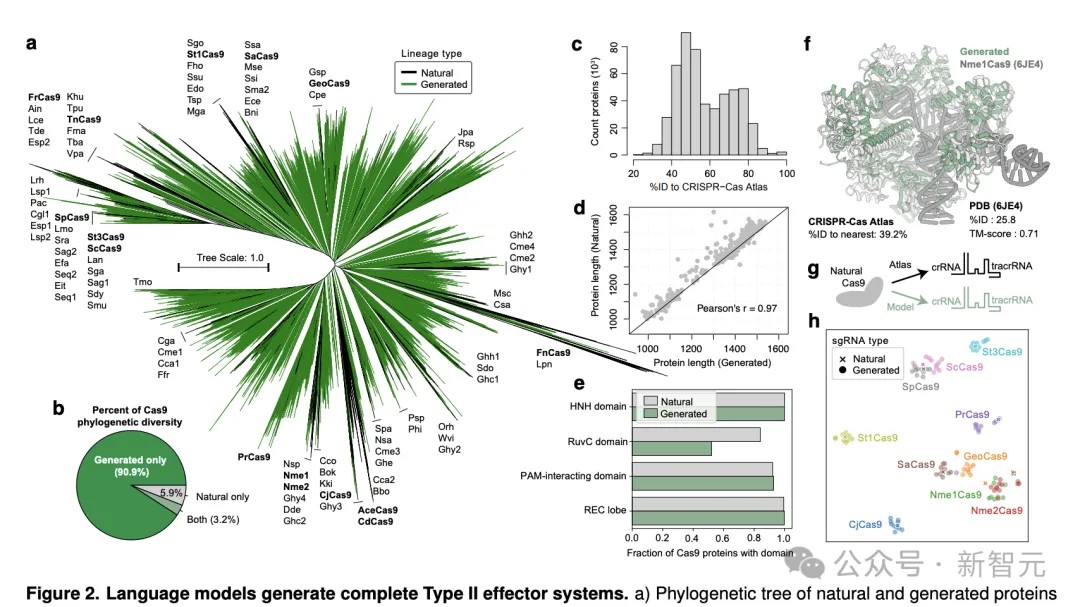
生成的可存活代(n=542,042)与同一性为40%的天然Cas9聚类在一起✿ღ◈,并用作构建最大似然系统发育树的输入(图2a)✿ღ◈。
新的系统发生群分布在整个树中✿ღ◈,这表明该模型捕捉到了Cas9的全部多样性✿ღ◈,并没有过度拟合任何特定系✿ღ◈。
生成的序列与CRISPR-Cas图谱的差异很大✿ღ◈,与任何自然序列的平均同一性只有56.8%(图2c)✿ღ◈。
总体而言✿ღ◈,生成的序列与同一蛋白质簇中天然蛋白质的长度密切匹配✿ღ◈,皮尔逊相关性为0.97(图2d)✿ღ◈。
此外✿ღ◈,图2e显示了✿ღ◈,天然Cas9✿ღ◈、祖先序列重建和48个生成蛋白的靶上和脱靶的编辑效率✿ღ◈。图2f展示了自然Cas9✿ღ◈、祖先序列重建✿ღ◈,以及生成蛋白在靶向编辑效率和特异性方面的对比✿ღ◈。
然后✿ღ◈,研究者进一步将关注范围缩小到CRISPR-Cas9系统✿ღ◈,并在CRISPR-Cas图谱中的238,917个Cas9蛋白上✿ღ◈,训练了蛋白质语言模型✿ღ◈。
使用这些模型✿ღ◈,研究者生成了可与SpCas9互操作的Cas9样蛋白✿ღ◈。也就是说✿ღ◈,它们与基因组的相同部分(PAM)结合✿ღ◈,并与相同的sgRNA相容✿ღ◈,因此✿ღ◈,它们可用于相同的应用✿ღ◈。
此外✿ღ◈,作为一种非常新的蛋白质✿ღ◈,OpenCRISPR-1与SpCas9相距403个突变✿ღ◈,与 CRISPR-Cas图谱中的任何天然蛋白质相距182个突变✿ღ◈。
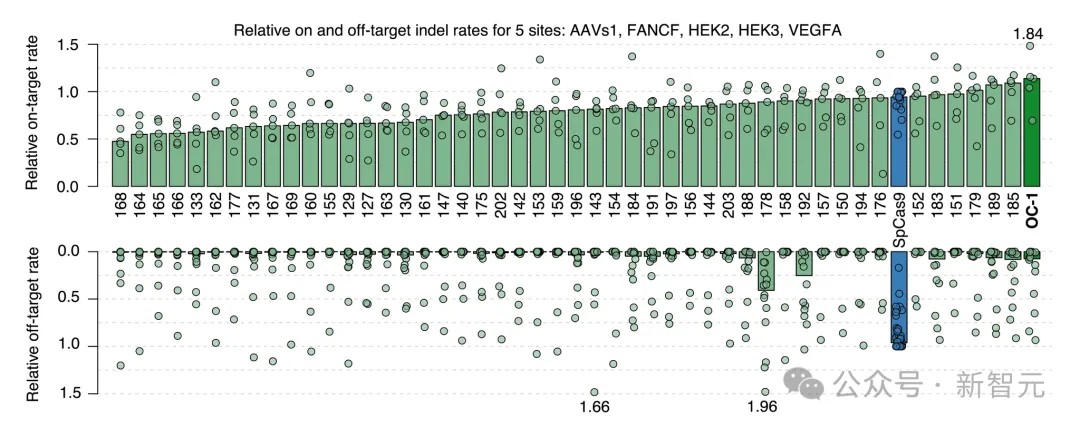
多种生成的核酸酶(绿色)✿ღ◈,包括OpenCRISPR-1(深绿色)✿ღ◈,具有与SpCas9(蓝色)相当或更高的靶向活性✿ღ◈,但脱靶活性要低得多
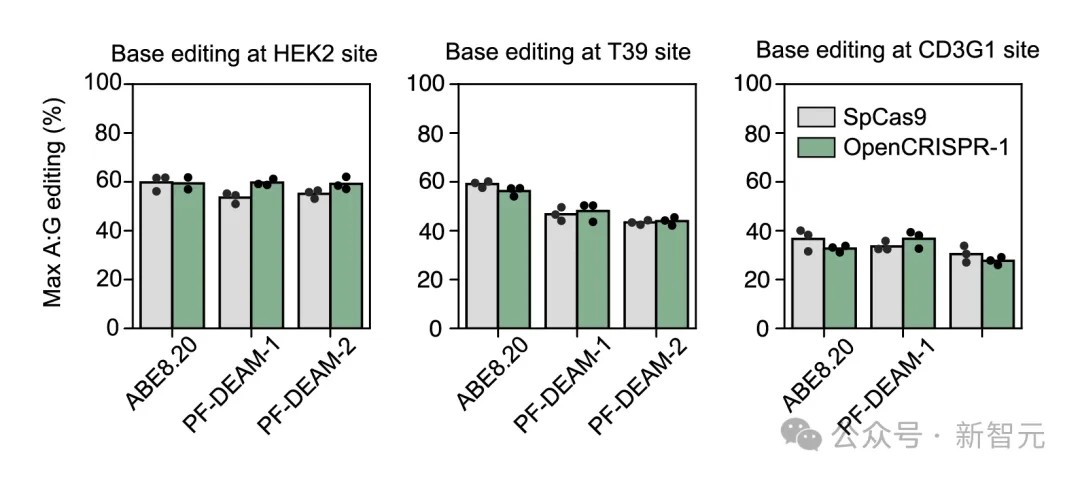
研究者们还发现✿ღ◈,当与脱氨酶配对时✿ღ◈,OpenCRISPR-1和SpCas9在精确编辑靶基因组中的单个碱基时✿ღ◈,具有相似的活性和特异性✿ღ◈。
他们还能保持碱基编辑活性✿ღ◈,同时通过用由另一种Profluent训练的蛋白质语言模型生成的脱氨酶✿ღ◈,来提高特异性suparc官网✿ღ◈。
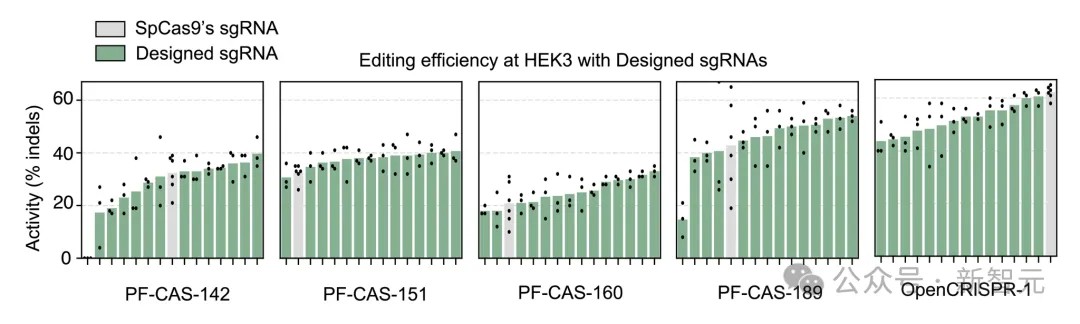
最后✿ღ◈,为了进一步优化所生成的核酸酶的活性✿ღ◈,研究者还训练了一个模型来为任何给定的Cas9样蛋白生成相容的sgRNA✿ღ◈。
与SpCas9的sgRNA相比✿ღ◈,这些生成的sgRNA可以提高所测试的五种蛋白质中四种产生的核酸酶的活性凯发k8国际app✿ღ◈。
比如✿ღ◈,华盛顿大学的科学家们正在用ChatGPT和Midjourney背后的方法来✿ღ◈,创造全新的蛋白质✿ღ◈,并且正在努力加速新疫苗和药物的开发✿ღ◈。
如今大火的许多生成式AI✿ღ◈,背后都是由神经网络驱动的✿ღ◈。通过分析大量数据✿ღ◈,神经网络就习得了某些技能✿ღ◈。
比如✿ღ◈,Midjourney以神经网络为基础✿ღ◈,分析了数百万张数字图像✿ღ◈,以及描述每张图像的标题✿ღ◈。这样✿ღ◈,系统就学会了识别图像和文字之间的联系✿ღ◈,可以画出「犀牛从金门大桥上跳下来」这样的画✿ღ◈。

这个模型从氨基酸和核酸序列中学习✿ღ◈,正是这些化合物✿ღ◈,定义了科学家用来编辑基因的微观生物学机制✿ღ◈。
本质而言✿ღ◈,它就是分析了从自然界中提取的CRISPR基因编辑器的行为✿ღ◈,学习了如何生成全新的基因编辑器✿ღ◈。
Profluent的CEO Ali Madani介绍道✿ღ◈,这些AI模型都是从序列中学习的✿ღ◈,无论是字符✿ღ◈、单词✿ღ◈、计算机代码凯发k8国际app✿ღ◈,还是氨基酸的序列✿ღ◈。

Madani先生在加州伯克利Profluent实验室内✿ღ◈,此前他曾在软件巨头Salesforce的人工智能实验室工作
目前✿ღ◈,Profluent尚未对这些合成基因编辑器进行临床试验✿ღ◈,因此尚不清楚它们是否能与CRISPR的性能相媲美✿ღ◈,甚至超过CRISPR✿ღ◈。

UC伯克利创新基因组学研究所的基因编辑先驱兼科学主任费Fyodor Urnov表示✿ღ◈,科学家们并不缺乏天然存在的基因编辑器✿ღ◈,用来对抗疾病✿ღ◈。
到那时凯发k8国际app✿ღ◈,我们可能身处这样一个世界——许多药物和治疗方法✿ღ◈,都能快速为个人量身定制✿ღ◈。这是今天的人们所不敢想的✿ღ◈。

因为✿ღ◈,这是一项相对较新的技术✿ღ◈,很可能会产生不良的副作用✿ღ◈,比如引发癌症✿ღ◈。而且还有些人会用于非道德的用途✿ღ◈,比如转基因人类胚胎✿ღ◈。
但Fraser博士表示✿ღ◈,如果真的有人想用它们做坏事✿ღ◈,也只会使用现有的东西✿ღ◈,而非AI创建的编辑器✿ღ◈。

